はじめに
前回に引き続き、Ruby Nokogiri Anemoneを使ってスクレイピングに挑戦したいと思います。
前回は特定のサイトのタイトルのみを取得する簡単なプログラムでしたので、今回は少しだけ進めて
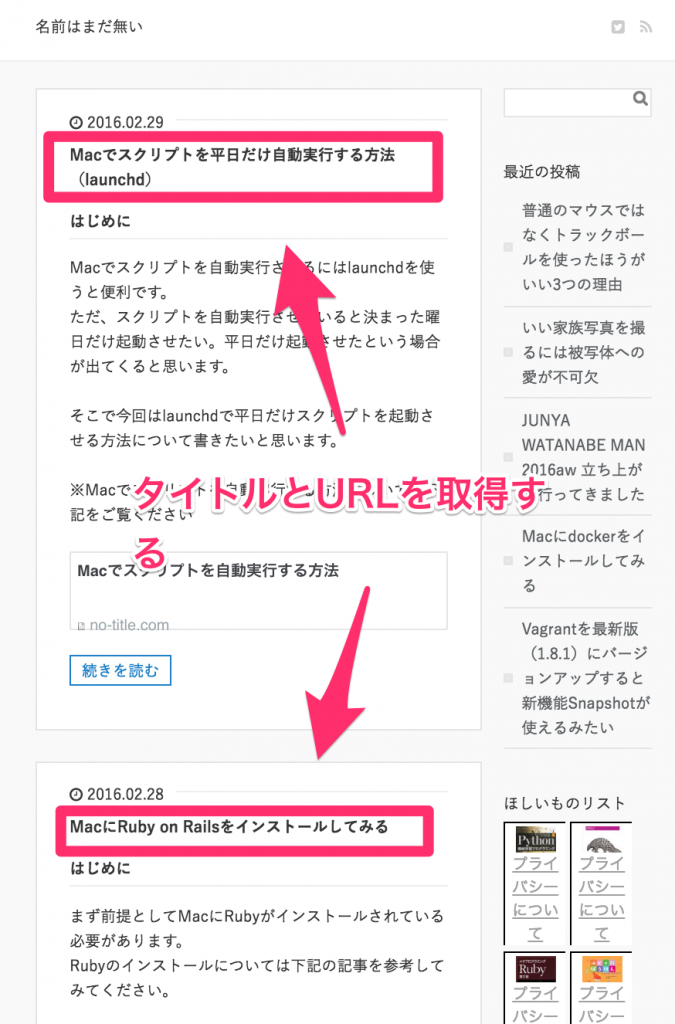
特定のブログのトップページの記事タイトルとURLを取得してみたいと思います。
今回も、私のブログを題材にしたいと思います。
私のブログはトップページに記事のリストが最新の記事から順に表示されてますので、
上から記事タイトルとURLを取得したいと思います。
プログラムを書いてみる
さっそくプログラムを書いてみたいと思います。
#必要なGemを読み込む
require 'bundler'
Bundler.require
#Anemoneのオプションを設定する
opts = {
depth_limit: 0, #検索の深さを設定
delay:1, #クローリングの間隔を設定(長めにしておきましょう)
user_agent: "My Crawler", #ユーザーエージェントを設定
obey_robots_txt:true #robot.txtに従う場合はtrue
}
# Anemone.crawlにURLとオプションを渡し、Anemoneを起動
Anemone.crawl("http://no-title.com/", opts) do |anemone|
# 指定したURLのすべてのページの情報を取得
anemone.on_every_page do |page|
#取得したページをdocメソッドに渡し、Nokogori形式にして、xpathで要素を絞り込む
page.doc.xpath("//h2[contains(@class,'post-title')]/a").each do |node|
title = node.xpath("./text()").to_s
link = node.xpath("./@href").to_s
puts title + "," +link
end
end
end
成功すると下記のようにタイトルとURLが出力されるはずです。
普通のマウスではなくトラックボールを使ったほうがいい3つの理由,http://no-title.com/gadget/trackball いい家族写真を撮るには被写体への愛が不可欠,http://no-title.com/camera/photo JUNYA WATANABE MAN 2016aw 立ち上がり行ってきました,http://no-title.com/fashion/junya-watanabe-man-2016aw Macにdockerをインストールしてみる,http://no-title.com/mac/docker Vagrantを最新版(1.8.1)にバージョンアップすると新機能Snapshotが使えるみたい,http://no-title.com/mac/vagrant1-8-1 Vagrantのプラグイン「vagrant-vbox-snapshot」の導入について,http://no-title.com/mac/vagrant-vbox-snapshot Vagrantのプラグイン「sahara」の導入について,http://no-title.com/mac/vagrant-sahara VirtualBoxとVagrantでCentOSをローカル環境に構築する方法,http://no-title.com/mac/virtualbox-centos Visual studio 2015でアプリケーションの発行をしようとすると「SignTool.exeが見つかりません」,http://no-title.com/programming/signtool iPhoneをMacから離すとMacを自動でロックするアプリ「Near Lock」Pro版が期間限定で無料,http://no-title.com/mac/near-lock
プログラムの解説
簡単にプログラムの解説をしてみます。
オプションの追加
前回はAnemoneオプションとして「depth_limit」だけ指定していましたが、今回はさらにオプション増やしました。
このオプションを増やした理由は、なるべくクローラーによってクロール対象のWEBサイトに迷惑をかけないようにするためです。
そもそもクローラーを作成するということで最初に記載すべきでしたが、クローラーを作成する前提として、対象のWEBサイトに迷惑を掛けてはいけません。
クローラーが原因で、対象のサイトのサーバーに負担がかかったり、他の閲覧者がサイトを見れなくなるような状態を引き起こせば、業務妨害とされる場合もあります。
※詳しくは下記の岡崎図書館事件を参考にしてください。
対象のサイトに負担をかけないように、今回はオプションによって下記の設定を行っています。
- robot.txtに従う
- クローリングの間隔を開ける
上記の設定をしていれば、絶対に大丈夫というわけではありませんが、最低限の設定としてオプションを指定しておくと良いと思います。
それと対象のサイトに利用規約のようなものがあれば一度目を通しておくと良いと思います。
構文解析
巡回の部分は前回簡単に説明しましたので、今回は構文解析について書こうと思います。
構文解析については構文解析ツールを使用すれば比較的簡単に実行することができ、今回のプログラムでは前回と同様、構文解析ツールとして「Nokogiri」を使用しています。Nokogoriのデータ指定方法はXPathとCSSセレクタの2種類があり、今回はXpathを使っています。
Xpathはrootノード、HTMLの場合はhtmlからタグ名を順番に指定することで要素を特定します。
たとえば、下記のようなHTMLがあるとします。
test website クローラーの作成
あああ
巡回方法
解析方法
まず、「title」要素を指定するには、下記のように書きます。
rootノードのhtmlの次にheadを指定し、headの中にtitleがあるので下記のような形になります。
html/head/title
次に「a」要素を指定するには、下記のようにします。
html/body/h2/p/a
さらに少し進んで、h2でclassがattentionのモノだけを取得するには、下記のように記述します。
html/body/h2[contains(@class,'attention')]/p/a
単にh2と指定したのではbody内にある、h2すべてを指定してしまいますので、h2の中でもattentionクラスを含むものだけをcontainsを使って指定しています。
XPathの記載方法については下記のチートシートが非常に良いので一度見てみると良いです。
ただ、上記のような単純なHTML構造を持つサイトのほうが現在は少ないので、それを上から順に辿っていく方法は現実的ではありません。
そこでブラウザの開発ツールを利用することで簡単にXpathを抽出することができるのでさっそく試してみましょう。
今回はfirefoxを使用します。
firefoxの場合、Firebugというアドオンが必要ですので、インストールしていない場合はインストールしておきましょう。
今回は本記事の題材でもある、私のブログの記事のタイトルの要素を指定してみましょう。
XPathで指定したい要素があるページに移動し、firebugを起動したら指定した要素を選択し、
選択されている要素を右クリックします。
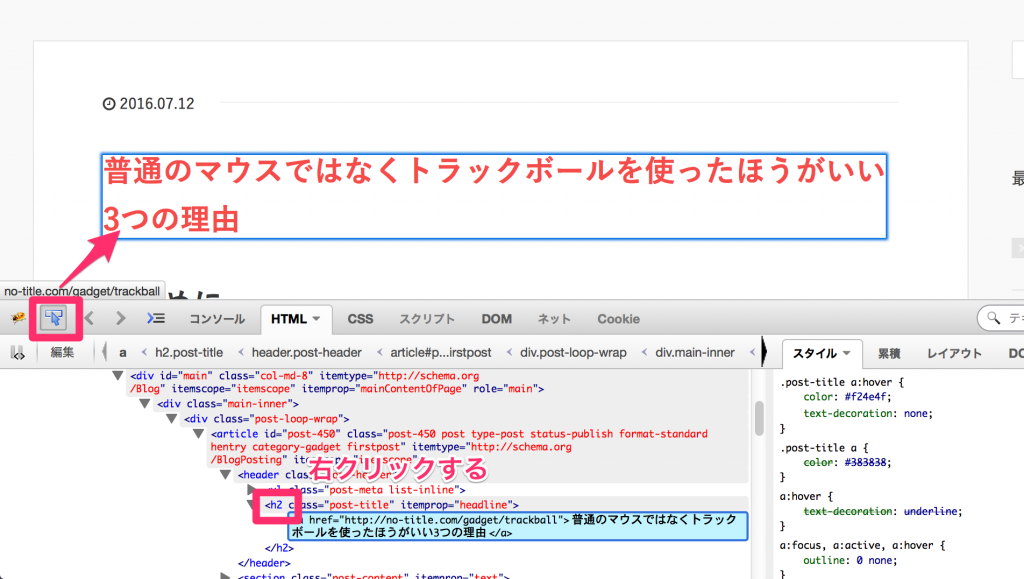
「Xpathをコピー」をクリックします。
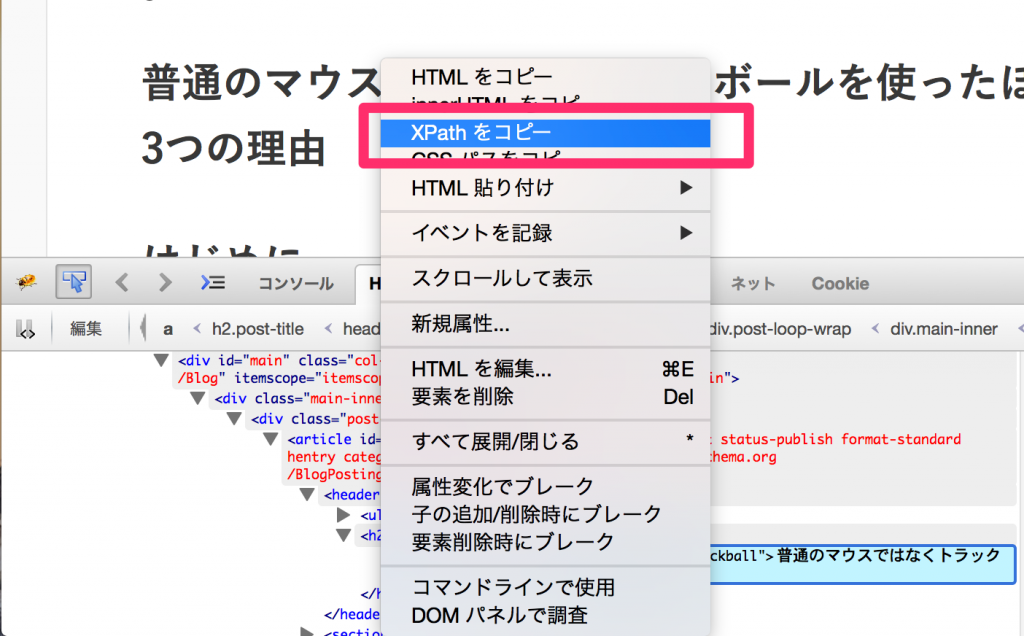
すると、クリップボードに下記のようなXpathがコピーされているはずです。
/html/body/div[2]/div/div[1]/div/div/article[1]/header/h2
ただ、上の指定の方法だと、上記で選択したh2要素、一つしか指定されないので、タイトルすべてを指定することはできません。そこで少し変更を加えます。
まず上記の指定方法だと長すぎるので短くします。XPathでは「//」を記載することで途中のパスを省略できます。
とりあえずarticle[1]より前は省略しておきましょう。
//article[1]/header/h2
更にHTMLの構造をよく見てみると、どうやらタイトルが記載されているのはh2タグの中のaタグであることがわかります。
さらにタイトルが記載されているaタグの上にあるh2のクラス名が「post-title」となっているので、クラス名が「post-title」となっているh2の中にあるaタグを指定すればタイトルをすべて抜き出すことができそうです。
なのでXPathは最終的に下記のような形になります。
//h2[contains(@class,'post-title')]/a
そして、取り出したa要素のテキストとURLをそれぞれ取り出せば、本記事のプログラムの目的を達成することができます。
今回は少し説明が長くなりすぎました(うまく説明できていないところがあるかもしれないので後々追記するかもしれません)。
また、次回に続きます。
参考書籍
